Documentation Index
Fetch the complete documentation index at: https://docs.statsig.com/llms.txt
Use this file to discover all available pages before exploring further.
What are Online Evals
Online evals let you grade your model output in production on real world use cases. You can run the “live” version of a prompt, but can also shadow run “candidate” versions of a prompt, without exposing users to them. Grading works directly on the model output, and has to work without a ground truth to compare against. Steps to do this in Statsig -- Create a Prompt. This contains the prompt for your task (e.g. Summarize ticket content. Don’t include email addresses or credit cards in the summary). Create a v2 prompt that improves on this.
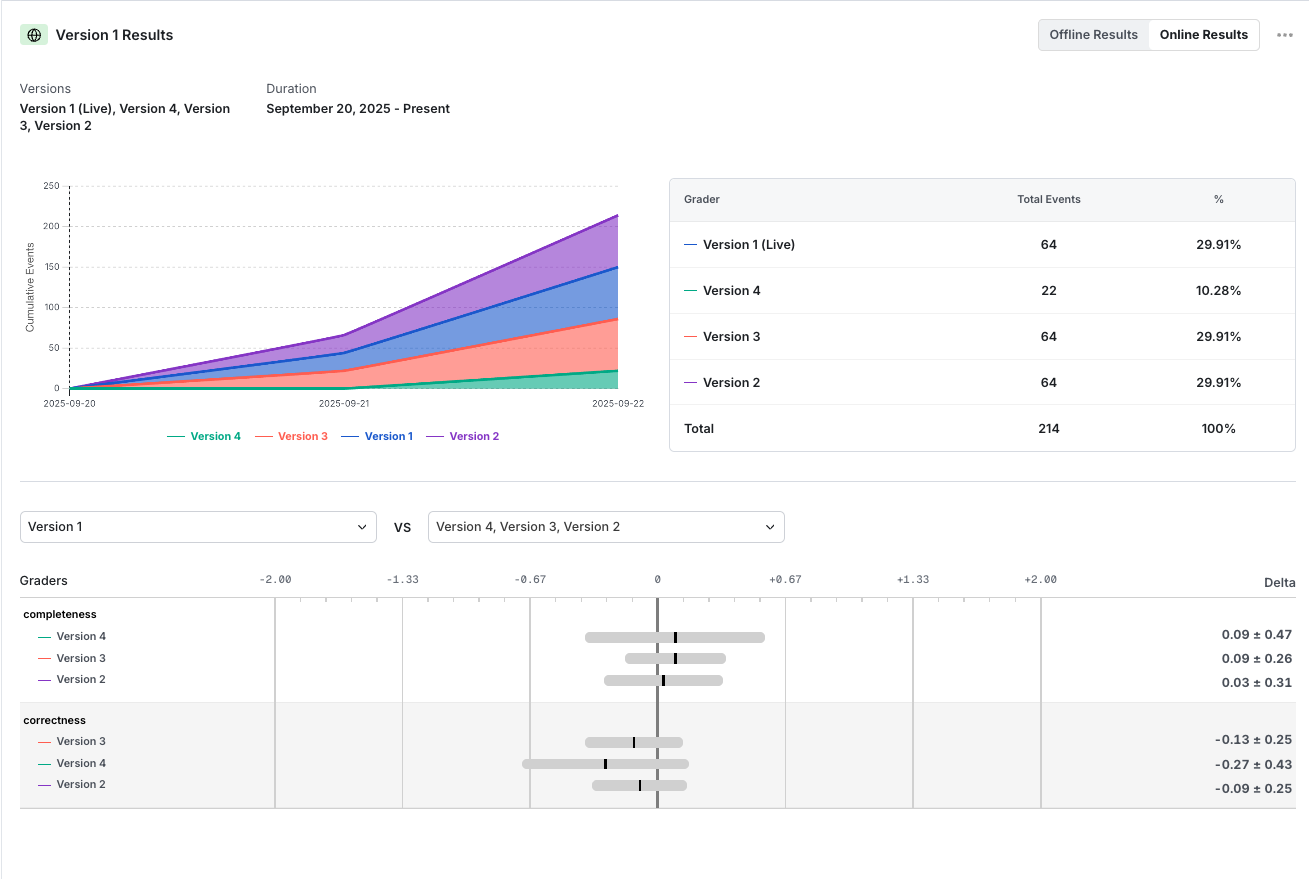
- In your app, use and produce model output using the v1 and v2 prompts. The output from v1 is rendered to the user; the output from v1 and v2 are judged by an LLM-as-a-judge.
- The grades from v1 and v2 are logged back to Statsig and can be compared there.
Online Evals is currently in beta. We are no longer accepting new beta customers at this time.
Create/analyze an online eval in 15 minutes
1. Identify the prompts you want to serve In Prompts, there are four prompt types: Live, Candidate, Draft and Archive. Before starting an online evaluation, it’s important to organize your prompt versions into these categories:- Live prompt is the version actively served to users.
- Candidate prompts are not shown to users but still served to your code. The user’s input is still processed against them, and their outputs are logged and graded alongside the live version.
- Draft prompts are the offline prompts you will iterate on in console, before deciding that you want to serve them. In order to start serving them, you should promote them to “Candidate” or “Live”
- Archive prompts are inactive versions that are not iterated on and kept offline.